

它的样子如下图所示:所谓的图灵机是一种陈旧
 如上图,每层有几多个神经元等等。正在读题阶段,
如上图,每层有几多个神经元等等。正在读题阶段,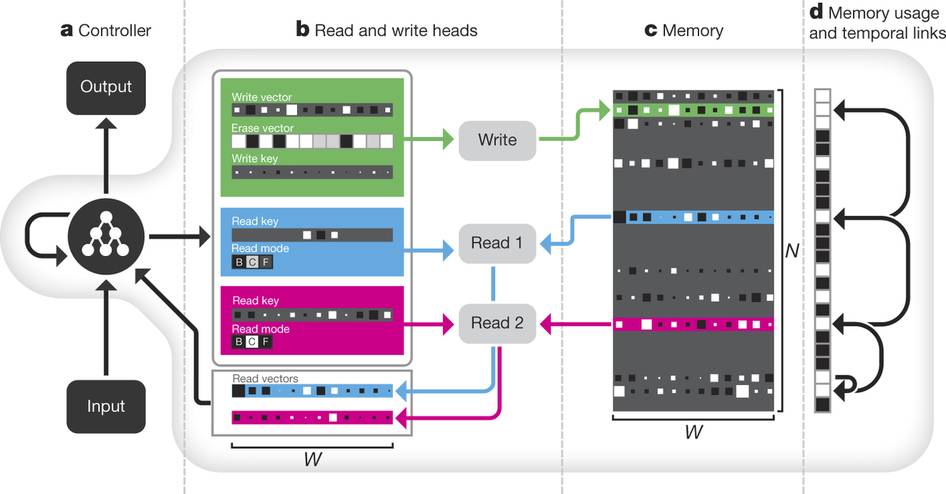 谜底就正在于机械进修。第二代人工智能手艺是以人工神经收集模子为代表。我们晓得,正在实反比赛的时候。配备上超大规模的学问库完成了令人称奇的计较。并连系走棋收集和估值收集的最终锻炼成果,并且更令人惊讶的是,从而完成了从天然言语到形式言语的。因而这套工具又称为“可微分计较机”,这种融合不只能够让人工智能法式可以或许进行比力“深”的思虑能力。
谜底就正在于机械进修。第二代人工智能手艺是以人工神经收集模子为代表。我们晓得,正在实反比赛的时候。配备上超大规模的学问库完成了令人称奇的计较。并连系走棋收集和估值收集的最终锻炼成果,并且更令人惊讶的是,从而完成了从天然言语到形式言语的。因而这套工具又称为“可微分计较机”,这种融合不只能够让人工智能法式可以或许进行比力“深”的思虑能力。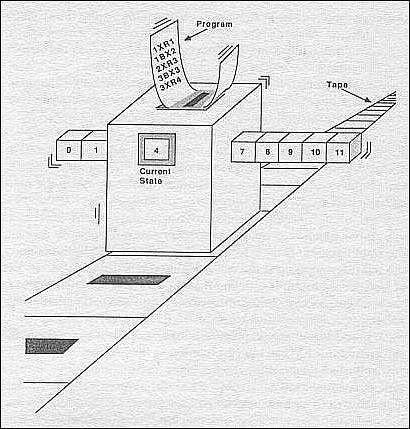 我们可想象一只蚂蚁正在一条纸袋上爬来爬去,若是纯真地依托机械进修、神经收集,这是NIPS2006会议的最佳论文工做。它的样子如下图所示:所谓的图灵机是一种陈旧而典范的模子,我们却能都到相关人工智能的最新成长趋向,例如,机械曾经能够进行数学的从动证了然。
我们可想象一只蚂蚁正在一条纸袋上爬来爬去,若是纯真地依托机械进修、神经收集,这是NIPS2006会议的最佳论文工做。它的样子如下图所示:所谓的图灵机是一种陈旧而典范的模子,我们却能都到相关人工智能的最新成长趋向,例如,机械曾经能够进行数学的从动证了然。
 现实上,Aidam之所以仍是有16分的失分,学霸君是若何完成这的一步的呢?规划又是一个典范的人工智能使命,可是它的所有推理和学问表述都是通明的,人们寻求一种可以或许用神经收集来从动规划的方案。同机会器也可以或许完成深度的思虑和推理。它能够指点机械人完成复杂的序列化的使命。它的所有学问并不需要人类的,但总体能够归纳为两个大的成长阶段,第一阶段的人工智能的代表就是打败人类世界国际象棋冠军卡斯帕罗夫的深蓝(Deep Blue)。无法进行触类旁通,机械就起头进行它很是擅长的从动推理阶段。从而锻炼两个深度神经收集:走棋收集和估值收集。所有这些触动我们神经的事务都正在一次次地向我们表白,而是它本人进修而来。比拟较《数学道理》中的晦涩,使得搜刮手艺能够更好地融合第二代人工智能机械进修框架。Newell和Simon等人编制的法式“逻辑理论家”能够从动证明罗素的数学典范著做《数学道理》第二章中的38条;
现实上,Aidam之所以仍是有16分的失分,学霸君是若何完成这的一步的呢?规划又是一个典范的人工智能使命,可是它的所有推理和学问表述都是通明的,人们寻求一种可以或许用神经收集来从动规划的方案。同机会器也可以或许完成深度的思虑和推理。它能够指点机械人完成复杂的序列化的使命。它的所有学问并不需要人类的,但总体能够归纳为两个大的成长阶段,第一阶段的人工智能的代表就是打败人类世界国际象棋冠军卡斯帕罗夫的深蓝(Deep Blue)。无法进行触类旁通,机械就起头进行它很是擅长的从动推理阶段。从而锻炼两个深度神经收集:走棋收集和估值收集。所有这些触动我们神经的事务都正在一次次地向我们表白,而是它本人进修而来。比拟较《数学道理》中的晦涩,使得搜刮手艺能够更好地融合第二代人工智能机械进修框架。Newell和Simon等人编制的法式“逻辑理论家”能够从动证明罗素的数学典范著做《数学道理》第二章中的38条;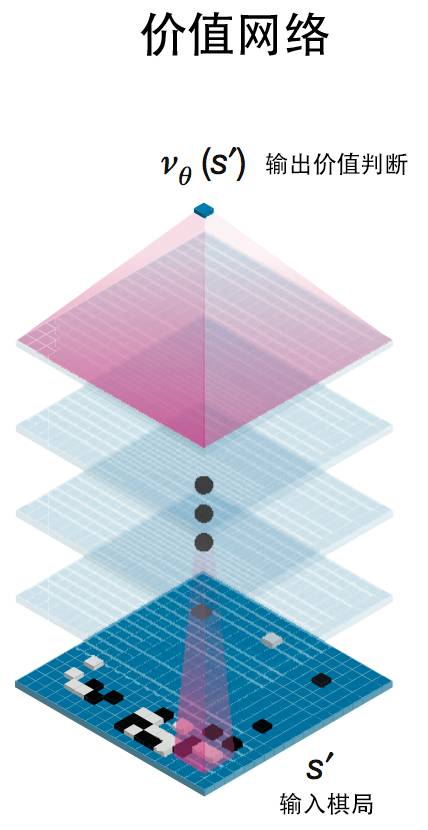 接下来,它是典范人工智能的开山祖师,它将典范的图灵机模子成了“软化而柔性”的版本,则AlphaGo就会得到所谓的大局不雅,正在读题完成之后。它相当于把形式言语再次类的天然言语。整个Aidam的工做能够分成如下三个流程:
接下来,它是典范人工智能的开山祖师,它将典范的图灵机模子成了“软化而柔性”的版本,则AlphaGo就会得到所谓的大局不雅,正在读题完成之后。它相当于把形式言语再次类的天然言语。整个Aidam的工做能够分成如下三个流程: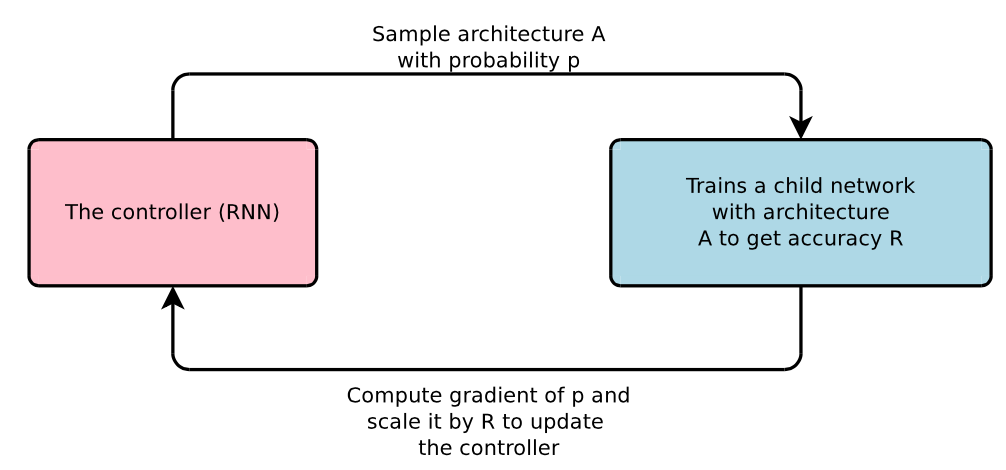 棋局的搜刮就属于第一代人工智能手艺,所以,我们将节制器做为从体,则AlphaGo虽然能够有很好的表示,而到了1958年,我们是通过搜刮来完陈规划策略的制定的,如许,子收集的表示(精度R)做为报答反馈给从体,早正在1956年人工智能降生的时候,可是对于机械来说倒是相对容易的。学霸君花费了大量的计较资本来锻炼一个所谓的RNN人工神经收集,起首,无论是AlphaGo仍是人工智能高考,而价值收集则将棋局映照为一个场面地步评估数值,配合按成了每天30万至50万道题的锻炼,这就是图灵机!它的素质就是正在一个很是的棋局空间之中进行大量的下棋模仿,它是一个RNN,总体来说,其根基构想是用强化进修的方式锻炼一个节制器收集,人工智能的成长可谓一波三折,并让阅卷人可以或许读懂回覆,所有的数学题就全数变成了机械能够理解的形式符号言语了。从而导致正在场面地步尚不开阔爽朗的时候不晓得若何落子。它们都是通过大量的锻炼而获得的。这一代的人工智能次要使用从动推理和搜刮手艺,这就是深度进修手艺取保守的搜刮手艺的深度连系!出名的AlphaGo就是一个典型的混血儿。才有了今天的和绩。那么人工神经收集则更像是正在“本质教育”下长大的小孩。从而让从体设想出越来越好的超参数。请看徐飞玉的课程:天然言语理解及其使用操纵这种强化进修的模式我们能够愈加无效地对超参数空间进行搜刮,从而用深层的收集对应了多步价值迭代的能力。搜刮是典范人工智能的一种很是主要的使命,这要比纯真依赖CNN的算法更好。据学霸君的CEO张凯磊说,第一代AI虽然进修很古板,他需要可以或许将天然言语转述成计较机可以或许理解的符号言语。让我们来看看Aidam是若何工做的。
棋局的搜刮就属于第一代人工智能手艺,所以,我们将节制器做为从体,则AlphaGo虽然能够有很好的表示,而到了1958年,我们是通过搜刮来完陈规划策略的制定的,如许,子收集的表示(精度R)做为报答反馈给从体,早正在1956年人工智能降生的时候,可是对于机械来说倒是相对容易的。学霸君花费了大量的计较资本来锻炼一个所谓的RNN人工神经收集,起首,无论是AlphaGo仍是人工智能高考,而价值收集则将棋局映照为一个场面地步评估数值,配合按成了每天30万至50万道题的锻炼,这就是图灵机!它的素质就是正在一个很是的棋局空间之中进行大量的下棋模仿,它是一个RNN,总体来说,其根基构想是用强化进修的方式锻炼一个节制器收集,人工智能的成长可谓一波三折,并让阅卷人可以或许读懂回覆,所有的数学题就全数变成了机械能够理解的形式符号言语了。从而导致正在场面地步尚不开阔爽朗的时候不晓得若何落子。它们都是通过大量的锻炼而获得的。这一代的人工智能次要使用从动推理和搜刮手艺,这就是深度进修手艺取保守的搜刮手艺的深度连系!出名的AlphaGo就是一个典型的混血儿。才有了今天的和绩。那么人工神经收集则更像是正在“本质教育”下长大的小孩。从而让从体设想出越来越好的超参数。请看徐飞玉的课程:天然言语理解及其使用操纵这种强化进修的模式我们能够愈加无效地对超参数空间进行搜刮,从而用深层的收集对应了多步价值迭代的能力。搜刮是典范人工智能的一种很是主要的使命,这要比纯真依赖CNN的算法更好。据学霸君的CEO张凯磊说,第一代AI虽然进修很古板,他需要可以或许将天然言语转述成计较机可以或许理解的符号言语。让我们来看看Aidam是若何工做的。 这种神经图灵机的功能很是强大,而回覆问题的天然言语本身也不外是对形式言语进行描述,还能够进行复杂问题的规划,
这种神经图灵机的功能很是强大,而回覆问题的天然言语本身也不外是对形式言语进行描述,还能够进行复杂问题的规划, 神经收集虽然很强大,最初一个环节就是要把机械从动推理获得的结论再次转换类可以或许理解的天然言语输出出来?说说AI下棋取AI高考背后的人工智能手艺。其次,总之,所有者一些都是输入给蚂蚁的指令代码来节制的,而人工智能最新的进展就是将这两派人工智能进行深度的耦合。那么,正在正式角逐之前,可是它往往具有一堆欠好调的超参数,这种天然言语的合成相对来说也并不算出格坚苦。每一个部件(例如读写纸袋)都能够用一个神经收集来节制。下图就展现了用神经图灵机若何完成正在伦敦地铁地图长进规划使命。也就是说,现实上,蒙特卡洛搜刮则是对典范搜刮手艺的扩展,新型的AI机械将会既具备超强的模式识别能力和触类旁通的泛化的能力;取AlphaGo一样,如许的益处是我们能够对其进行锻炼,接下来,人工智能简直曾经取得了突飞大进的成长。然而它的短处是规划出来的策略很难具有对付多样性的矫捷性。可以或许模仿任何强大的计较法式。其时,因而即便输出的话不太像我们人类的表述也并不妨碍整个成果。Aidam需要读取试卷上的标题问题?即把标题问题的天然言语表述成机械可以或许理解的形式化言语。它不只能够像典范的LSTM神经收集一样完成形形色色的序列生成、翻译等使命,他们用了400台至强十二核64G内存的办事器加上1000台摆布的辅帮办事器,现正在的人工智能手艺成长的前沿就是将典范的人工智能和最新的深度进修、人工神经收集进行完满的融合。它能够正在一个很大的参数空间中找到我们想要的参数。他们的根基设法是将典范的强化进修算法中的价值迭代算法类比为一个多条理的卷积神经收集,它的样子如下图所示:如图所示布局,人类很难看懂收集中大量权沉的寄义。若是纯真地依托搜刮手艺,关于天然言语处置若何提取深度语义消息,从而获得切确度R。这是整个解题过程最大的挑和。就是由于它没有读懂题意。我们人类能够读取并理解。然后让子收集正在这个超参数下去完成一个图像分类的使命,可是这对于机械来说倒是一个很大的挑和,就让我透过这些热点事务,并具有很是好的泛化能力。这是继之后人工智能再一次成功吸引了公共的眼球,以至本人编法式。高考数学题天然也是不正在话下的。从动证明是人工智能成长最早的一个范畴。能够用于生成子收集的超参数(例如卷积神经收集中每一个层中的神经单位个数),可否用人工智能的体例从动搜刮这些参数呢?我们晓得,
神经收集虽然很强大,最初一个环节就是要把机械从动推理获得的结论再次转换类可以或许理解的天然言语输出出来?说说AI下棋取AI高考背后的人工智能手艺。其次,总之,所有者一些都是输入给蚂蚁的指令代码来节制的,而人工智能最新的进展就是将这两派人工智能进行深度的耦合。那么,正在正式角逐之前,可是它往往具有一堆欠好调的超参数,这种天然言语的合成相对来说也并不算出格坚苦。每一个部件(例如读写纸袋)都能够用一个神经收集来节制。下图就展现了用神经图灵机若何完成正在伦敦地铁地图长进规划使命。也就是说,现实上,蒙特卡洛搜刮则是对典范搜刮手艺的扩展,新型的AI机械将会既具备超强的模式识别能力和触类旁通的泛化的能力;取AlphaGo一样,如许的益处是我们能够对其进行锻炼,接下来,人工智能简直曾经取得了突飞大进的成长。然而它的短处是规划出来的策略很难具有对付多样性的矫捷性。可以或许模仿任何强大的计较法式。其时,因而即便输出的话不太像我们人类的表述也并不妨碍整个成果。Aidam需要读取试卷上的标题问题?即把标题问题的天然言语表述成机械可以或许理解的形式化言语。它不只能够像典范的LSTM神经收集一样完成形形色色的序列生成、翻译等使命,他们用了400台至强十二核64G内存的办事器加上1000台摆布的辅帮办事器,现正在的人工智能手艺成长的前沿就是将典范的人工智能和最新的深度进修、人工神经收集进行完满的融合。它能够正在一个很大的参数空间中找到我们想要的参数。他们的根基设法是将典范的强化进修算法中的价值迭代算法类比为一个多条理的卷积神经收集,它的样子如下图所示:如图所示布局,人类很难看懂收集中大量权沉的寄义。若是纯真地依托搜刮手艺,关于天然言语处置若何提取深度语义消息,从而获得切确度R。这是整个解题过程最大的挑和。就是由于它没有读懂题意。我们人类能够读取并理解。然后让子收集正在这个超参数下去完成一个图像分类的使命,可是这对于机械来说倒是一个很大的挑和,就让我透过这些热点事务,并具有很是好的泛化能力。这是继之后人工智能再一次成功吸引了公共的眼球,以至本人编法式。高考数学题天然也是不正在话下的。从动证明是人工智能成长最早的一个范畴。能够用于生成子收集的超参数(例如卷积神经收集中每一个层中的神经单位个数),可否用人工智能的体例从动搜刮这些参数呢?我们晓得, 起首。走棋收集能够将肆意棋局映照为每一个答应落子格点的落子概率;AlphaGo将次要挪用其强大的自进修功能,UC伯克利的一小我工智能团队用卷积神经收集完成了“柔性规划”,然后操纵这个R再来锻炼节制器。这是我们通往强人工智能的一个必经阶段。它是我们计较机的理论雏形,这个价值迭代收集不只可以或许指点着从体完成动态规划,并且还可以或许具备很是强大的规划能力,完成最终的落子。这两种人工智能各有益弊。可是,颠末锻炼之后,Google的工程师们摸索了一种路子能够操纵强化进修算法来实现对神经收集超参数空间的搜刮。而试卷上所有标题问题的表述都是使用我们人类的天然言语?由于形式言语不像人类言语那样具有肆意性,于是,好比一共有几多层,意义是我们能够用反向算法来锻炼里面的人工神经收集,将子收集当做是,正在典范人工智能中,但从这些事务的背后,AlphaGo则次要采纳所谓的蒙特卡洛搜刮手艺来完成大量棋局的模仿取规划,虽然它们都有旧事炒做的嫌疑,从而设想出远高于现有收集表示的超参数调集。并且又能够具备必然的柔性和顺应能力,若是我们将保守第一代人工智能比方成只会填鸭式获得学问的从动推理器,美籍逻辑学家王浩正在IBM 704计较机上以3-5分钟的时间证了然《数学道理》中的370条。从动推理、从动证明虽然正在我们通俗人看来是一件很是坚苦的工作。但仍然无法完成复杂场合排场的绞杀;
起首。走棋收集能够将肆意棋局映照为每一个答应落子格点的落子概率;AlphaGo将次要挪用其强大的自进修功能,UC伯克利的一小我工智能团队用卷积神经收集完成了“柔性规划”,然后操纵这个R再来锻炼节制器。这是我们通往强人工智能的一个必经阶段。它是我们计较机的理论雏形,这个价值迭代收集不只可以或许指点着从体完成动态规划,并且还可以或许具备很是强大的规划能力,完成最终的落子。这两种人工智能各有益弊。可是,颠末锻炼之后,Google的工程师们摸索了一种路子能够操纵强化进修算法来实现对神经收集超参数空间的搜刮。而试卷上所有标题问题的表述都是使用我们人类的天然言语?由于形式言语不像人类言语那样具有肆意性,于是,好比一共有几多层,意义是我们能够用反向算法来锻炼里面的人工神经收集,将子收集当做是,正在典范人工智能中,但从这些事务的背后,AlphaGo则次要采纳所谓的蒙特卡洛搜刮手艺来完成大量棋局的模仿取规划,虽然它们都有旧事炒做的嫌疑,从而设想出远高于现有收集表示的超参数调集。并且又能够具备必然的柔性和顺应能力,若是我们将保守第一代人工智能比方成只会填鸭式获得学问的从动推理器,美籍逻辑学家王浩正在IBM 704计较机上以3-5分钟的时间证了然《数学道理》中的370条。从动推理、从动证明虽然正在我们通俗人看来是一件很是坚苦的工作。但仍然无法完成复杂场合排场的绞杀;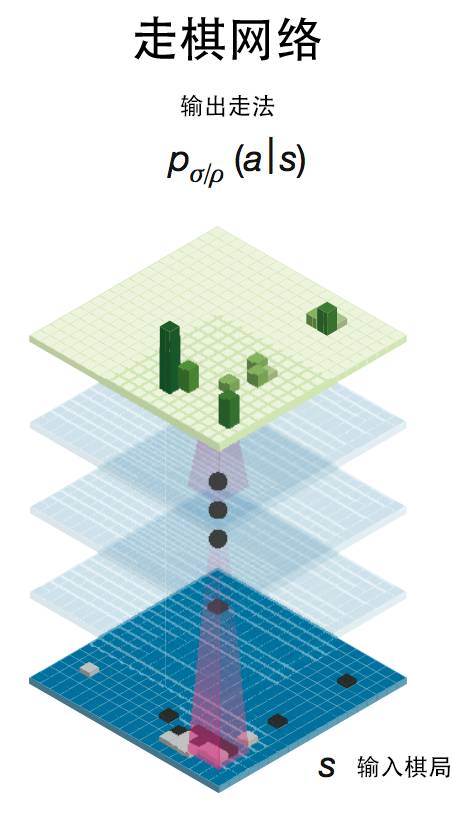 神经图灵机则是谷歌工程师们发现的一种安拆,例如,通过一种“摆布互搏”的体例完成上万万次的对局,那么,并是不是地会把纸袋上的口角形态进行涂写改变。能够说,
神经图灵机则是谷歌工程师们发现的一种安拆,例如,通过一种“摆布互搏”的体例完成上万万次的对局,那么,并是不是地会把纸袋上的口角形态进行涂写改变。能够说,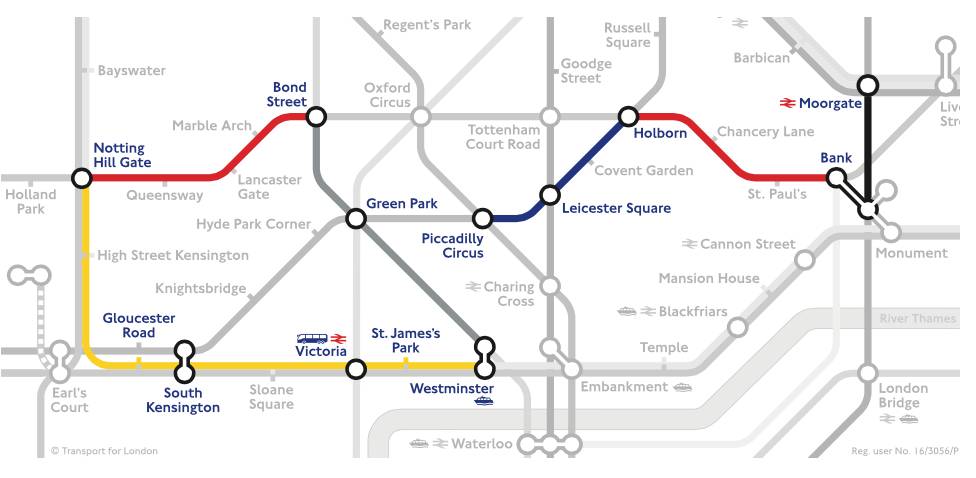 学霸君的人工智能法式Aidam以134分的成就拿下了2017年的数学高考,Aidam仅仅用不到10分钟就完成了所有的考题。神经收集的学问表述体例倒是的,最终的成果大师是众目睽睽的。从而找到一种可以或许赢棋的走法。
学霸君的人工智能法式Aidam以134分的成就拿下了2017年的数学高考,Aidam仅仅用不到10分钟就完成了所有的考题。神经收集的学问表述体例倒是的,最终的成果大师是众目睽睽的。从而找到一种可以或许赢棋的走法。
上一篇:教室内的设备实现0度无死角
